Exploring Vector Databases: A Game-Changer in AI Technology
Part 2 of the Generative AI Series
I am a Journalist-turned-Software Engineer. I love coding and the associated grind of learning every day. A firm believer in social learning, I owe my dev career to all the tech content creators I have learned from. This is my contribution back to the community.
Let us first understand the "Vector" part in the Vector Database.
What is Vector Data?
What happens when you see an apple?
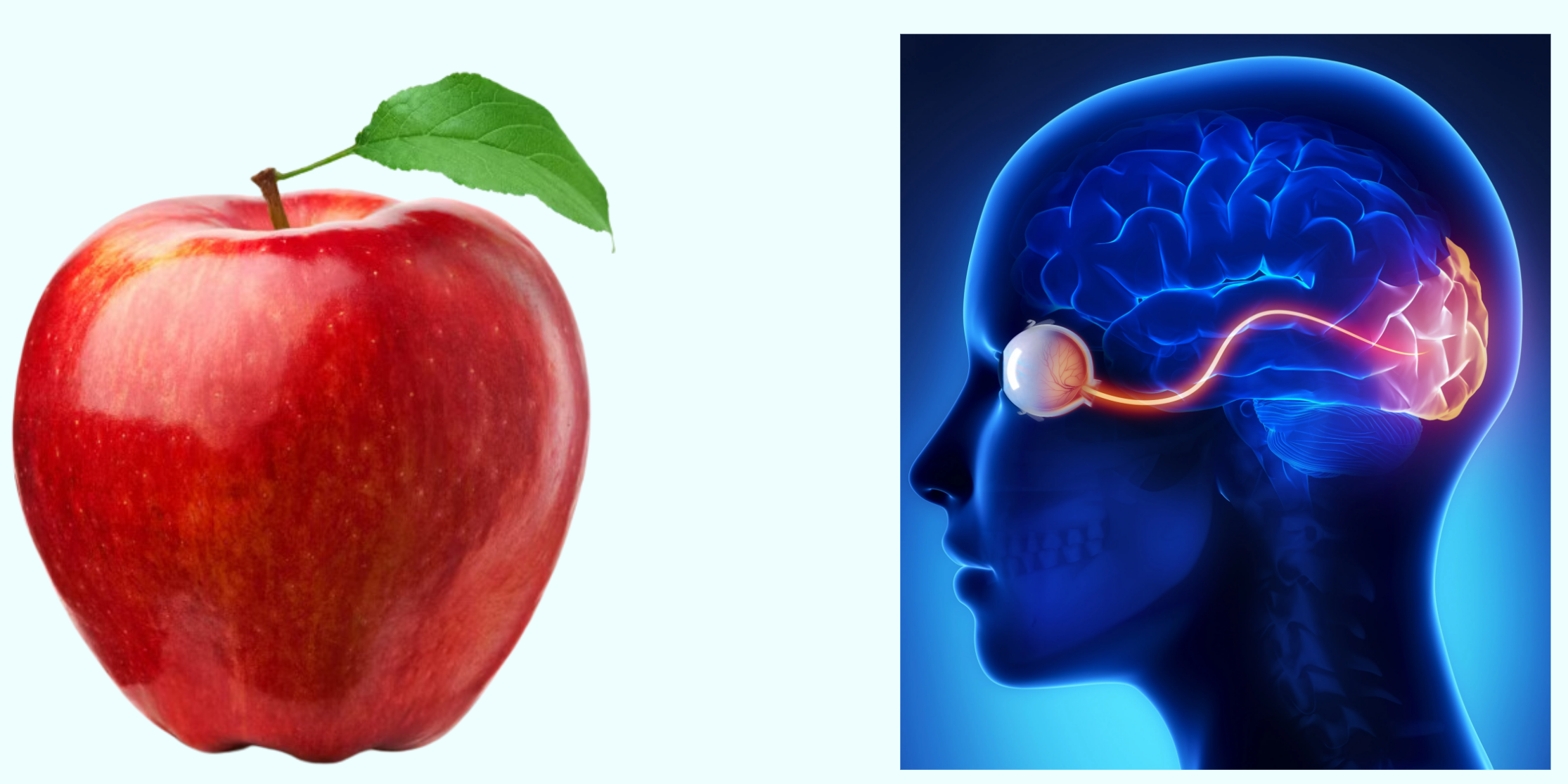
When you set your eyes on an apple, your brain goes through a two-step process.
As light enters your eyes, it hits the retina. Just as a camera captures the intensity of light, your retina records the brightness of the apple and translates it into neural signals.
Now, these neural signals embark on a journey to the visual cortex, which resides at the back of your brain.
The visual cortex consists of different layers, each with its own role in analyzing the signals.
At the initial layer, the signals are decoded to identify the basic features of the apple, such as its edges. As the signals travel deeper into the visual cortex, more intricate details come to light. Curves, shading, and contours are recognized, painting a vivid picture of the apple in your mind.
The vectorized representation of the apple is then sent to other parts of the brain, such as the temporal lobe.
Here, advanced functions like object recognition, face recognition, and visual memory take place. It's important to note that these functions rely not on the original image but on the rich representation built by the visual cortex.
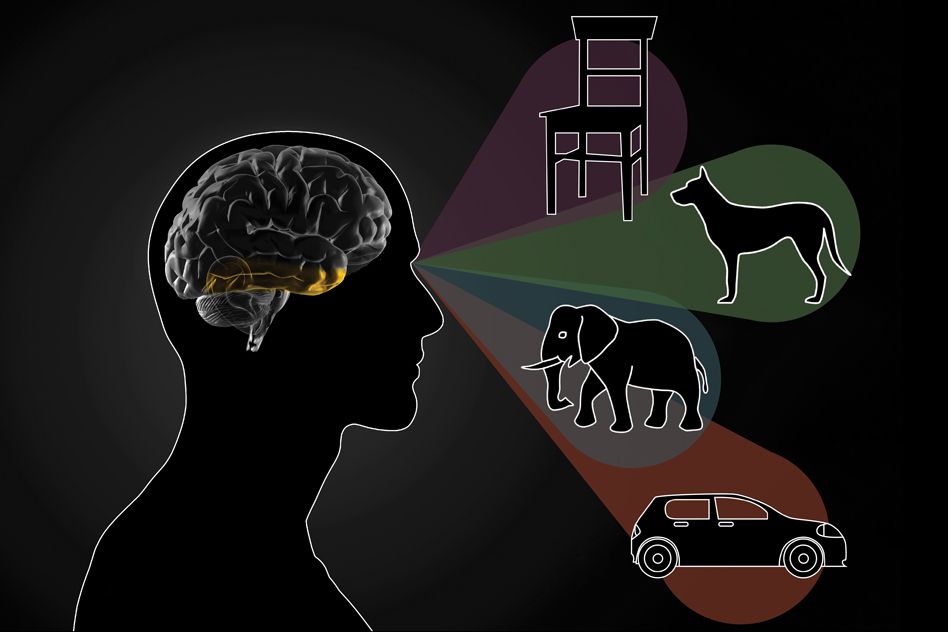
This process mirrors how artificial neural networks operate. Just as our brain transforms neural signals, machine learning algorithms can convert images or text into a different representation called vectors.
For instance, when it comes to image recognition, convolutional neural networks can transform images into vector representations. This enables us to perform diverse tasks, like finding similarities, searching for specific products, and even detecting scenes within images.
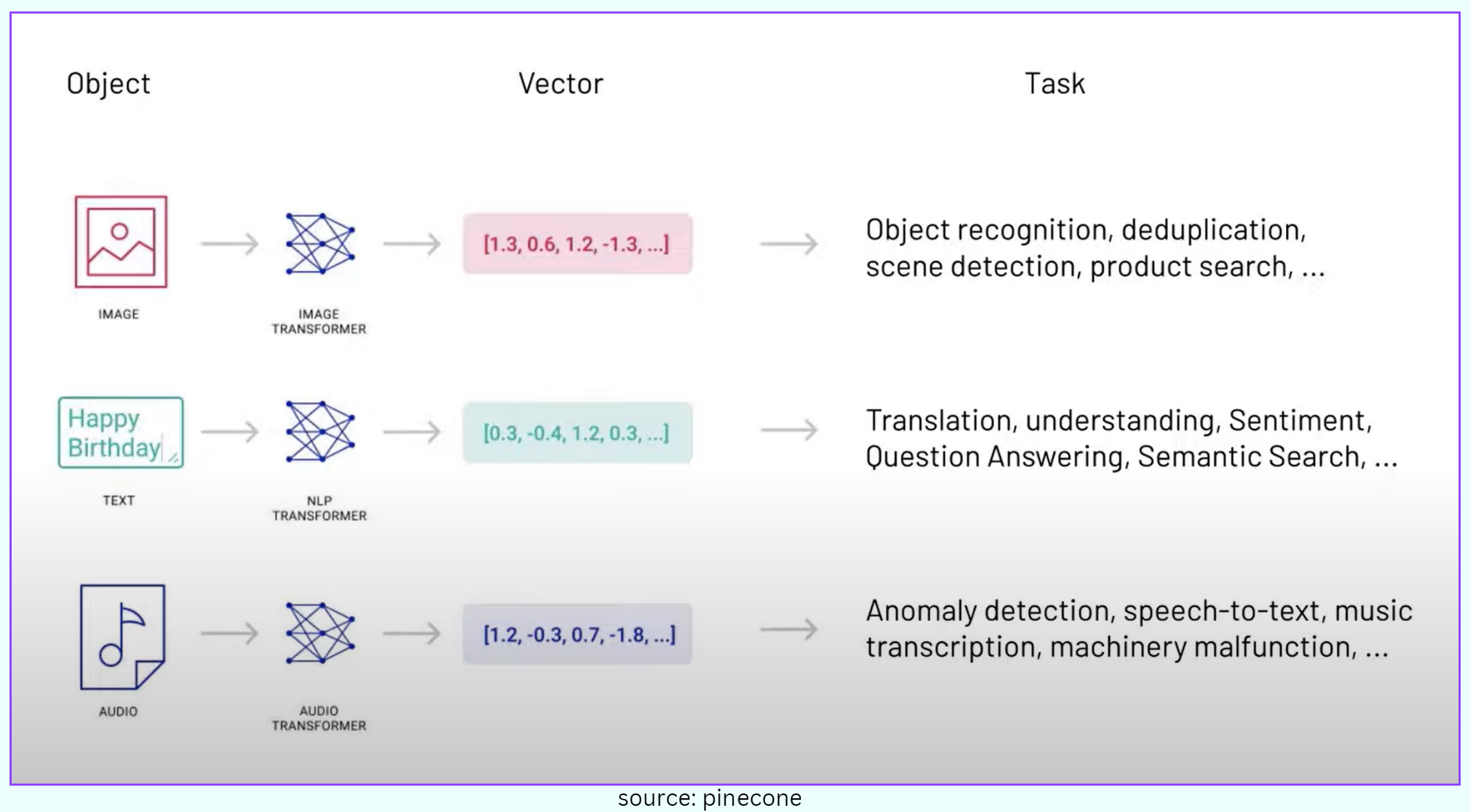
While vector data provides a representation of the raw data itself, vector embeddings take this concept to another level.
Instead of merely representing the data, embeddings aim to capture the semantic meaning and contextual relationships embedded within the data. They transform words, phrases, or even entire texts into numerical vectors that encapsulate the essence of their semantic properties.
What are Vector Embeddings?
Vector embeddings, also known as word embeddings, are numerical representations of words or phrases that capture their meaning and semantic relationships. They are generated using machine learning algorithms trained on large amounts of text data.
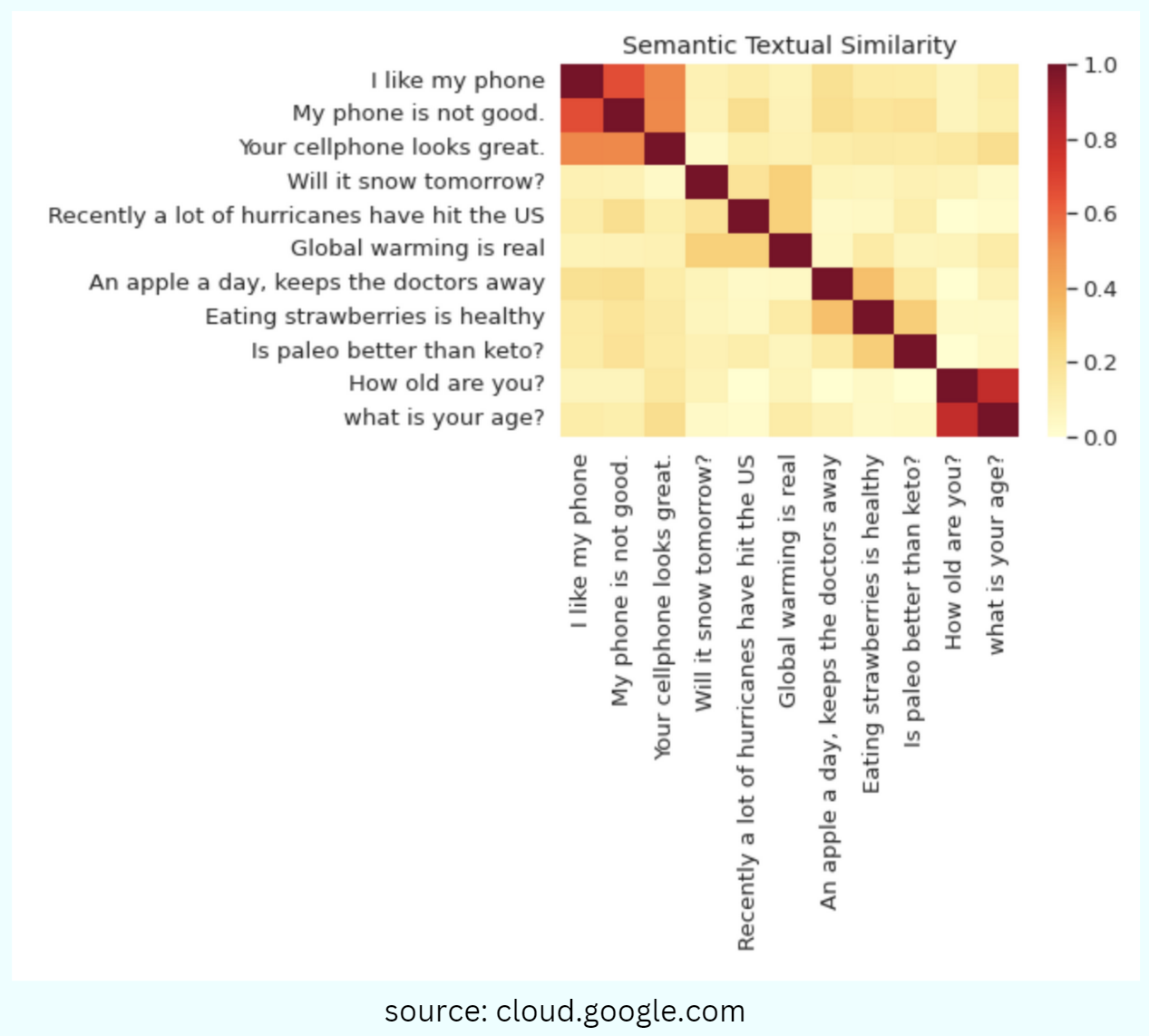
Embeddings are a way of representing data–almost any kind of data, like text, images, videos, users, music, whatever–as points in space where the locations of those points in space are semantically meaningful.
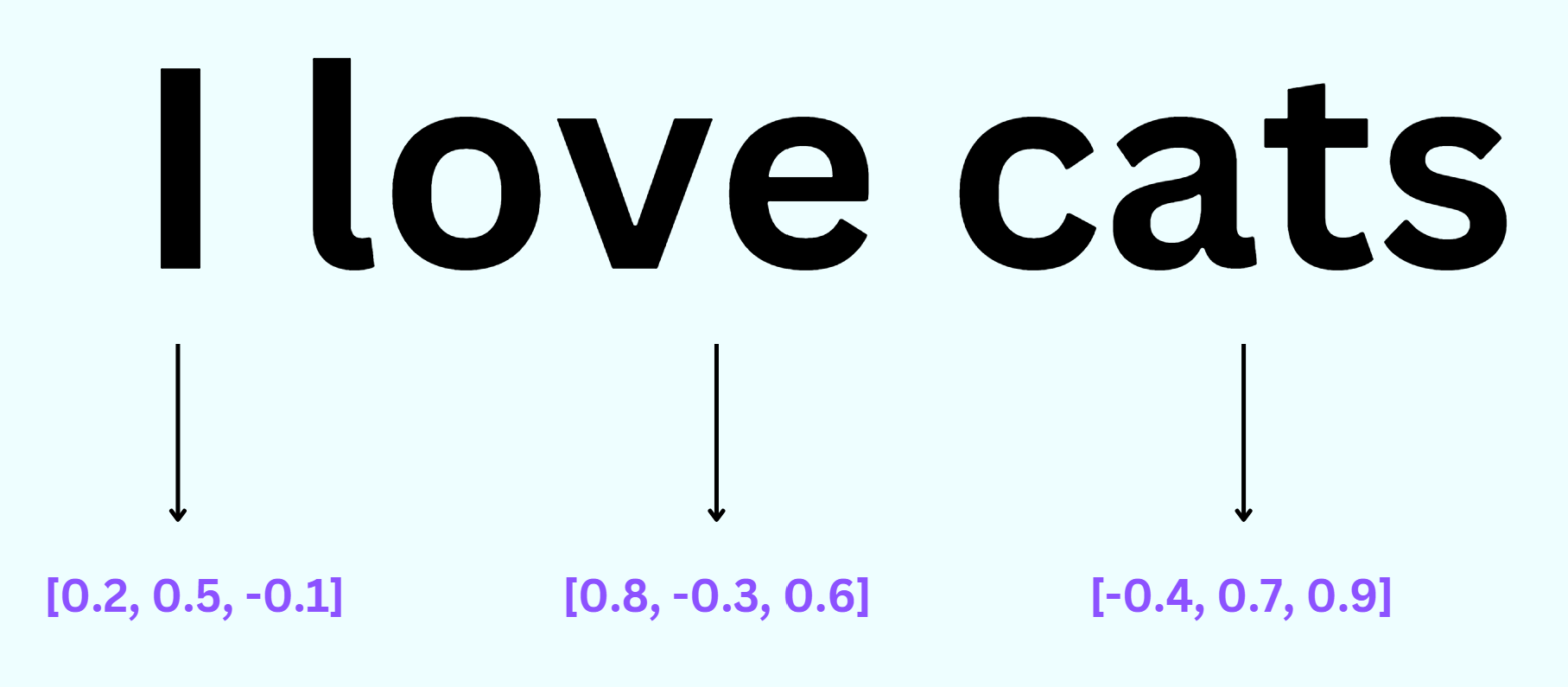
Imagine we have a dataset of sentences, including the sentence "I love cats." A vector embedding model would analyze the words in this sentence and assign each word a unique vector representation. For example:
"I" could be represented by the vector [0.2, 0.5, -0.1]
"love" could be represented by the vector [0.8, -0.3, 0.6]
"cats" could be represented by the vector [-0.4, 0.7, 0.9]
These vectors encode the meaning of the respective words in a numerical format. The values in each vector capture different aspects of the word's semantics.
In the above vectors, the first value could represent positivity/negativity, the second value could represent intensity, and the third value could represent emotion.
How is a large text dataset represented?
An embedding model analyzes the words, sentences, or paragraphs together to create cohesive representations. This process takes into account the context and meaning of words in relation to the surrounding text.
For example, let's say we have a collection of essays about different animals. The vector embeddings model would consider the words used across all the essays, identify patterns, and assign numerical vectors to each word. These vectors capture the semantic meaning and contextual information within the entire corpus.
This approach enables us to process and understand large volumes of text efficiently. Vector embeddings provide a compact representation of the information present in the texts, allowing for more effective text analysis, document clustering, and information retrieval in various natural language processing applications.
Vector embeddings are vital for training AI models. To fully leverage their advantages, it is essential to have a specialized database that can efficiently store, index, and retrieve these embeddings. This dedicated database maximizes the benefits of using vector embeddings in AI applications.
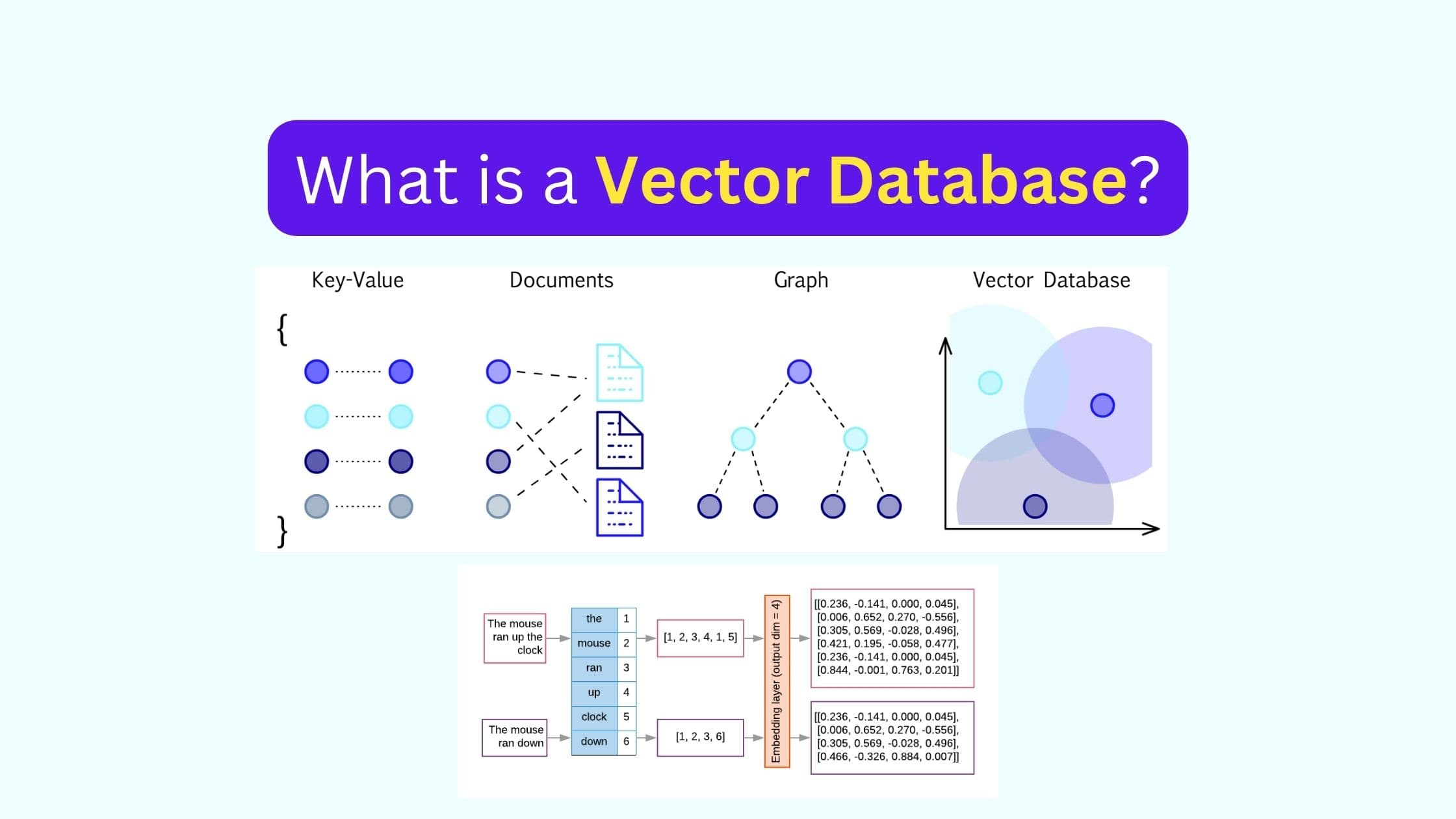
What is a Vector Database?
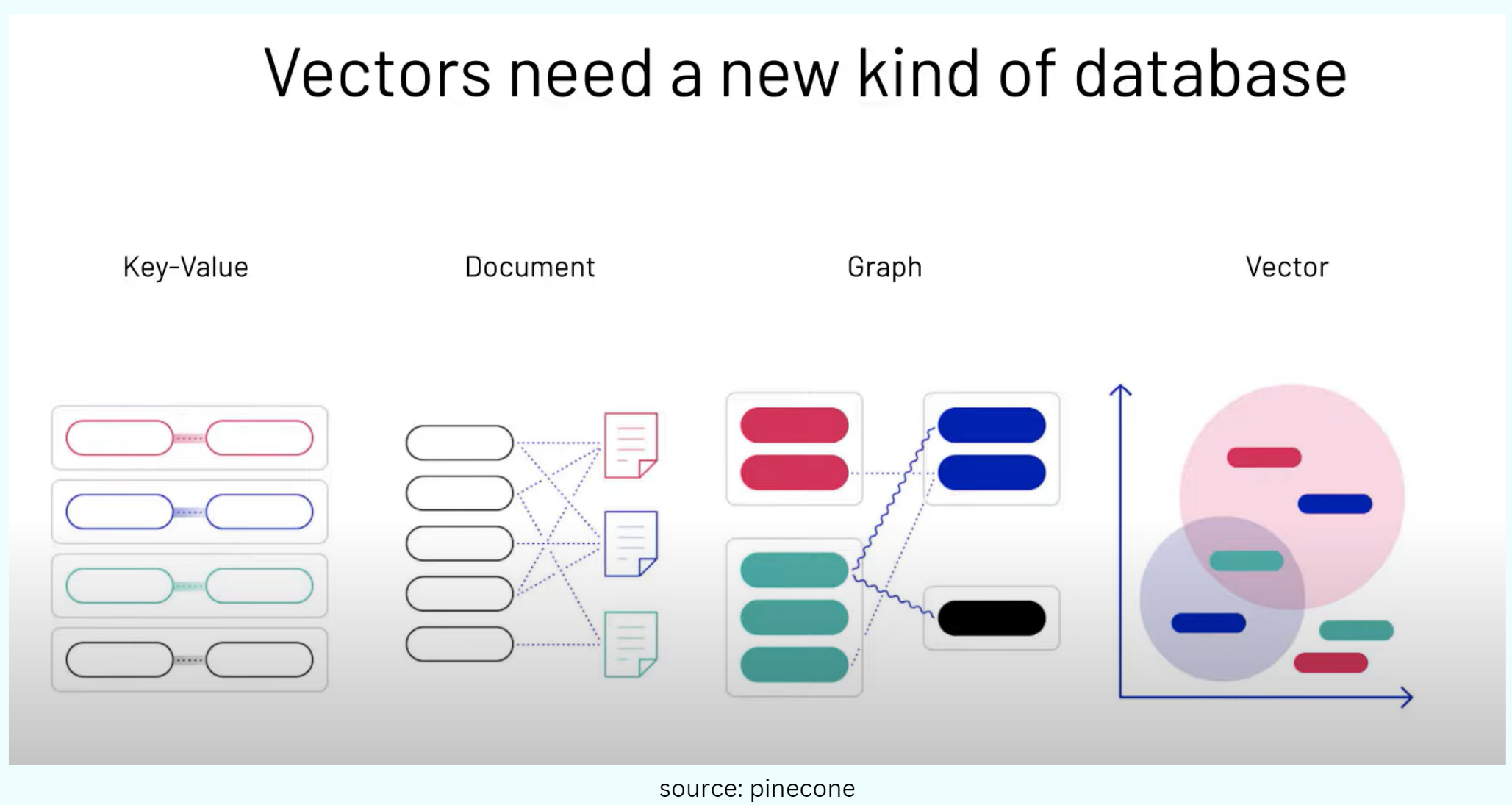
A vector database is a type of database that stores data as high-dimensional vectors
The main advantage of a vector database is that it allows for fast and accurate similarity search and retrieval of data based on their vector distance or similarity.
This means that instead of using traditional methods of querying databases based on exact matches or predefined criteria, you can use a vector database to find the most similar or relevant data based on their semantic or contextual meaning.
How is data stored and retrieved?
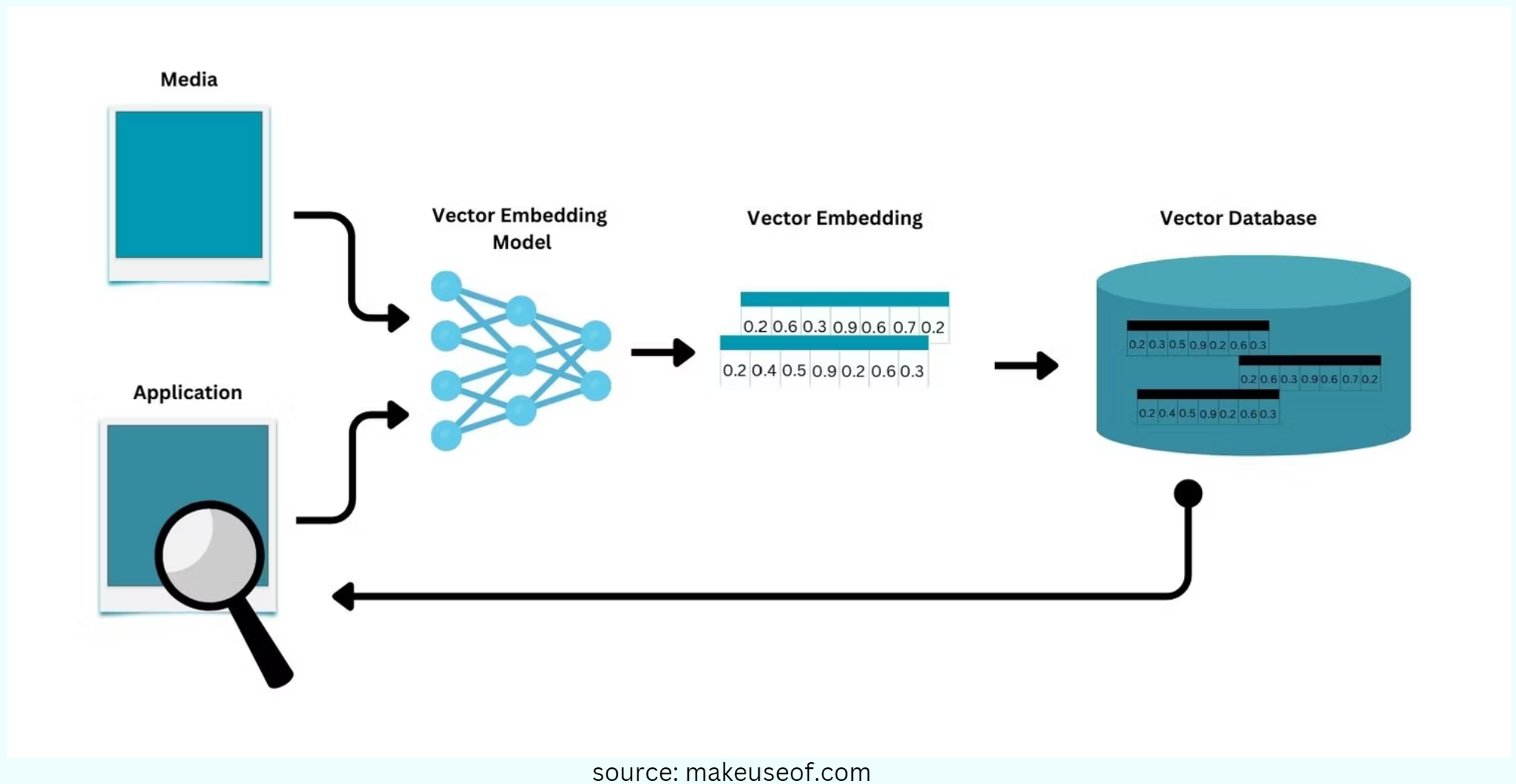
It's a 3-step process.
Let's say you want to parse and store a lengthy PDF.
Create vector embeddings of the PDF by using relevant embedding models
Store and index the generated embeddings into the vector database
When an application issues a query, the query must first go through the same vector embedding model used to generate the stored data on the vector database. The generated vector query is then placed on the vector database, where the nearest vector is then retrieved as the most fitting answer to the query.
Popular Vector Databases
Faiss (22.8k ⭐) is a library developed primarily at Meta's Fundamental AI Research group. It enables efficient similarity search and clustering of dense vectors, even for sets of vectors that may not fit in RAM
Milvus (20.3k ⭐) is an open-source vector database capable of managing trillions of vector datasets. It supports multiple vector search indexes and has built-in filtering functionalities
Qdrant (11.2k ⭐) is a vector similarity search engine and database. It offers a production-ready service with a convenient API for storing, searching, and managing vectors along with additional payload
Elasticsearch (64.2k ⭐) is a distributed search and analytics engine that supports different types of data. It introduced vector field support in version 7.10, allowing the storage of dense numeric vectors
Weaviate (6.5k ⭐) is an open-source vector database capable of storing data objects and vector embeddings from ML-models. It can seamlessly scale to handle billions of data objects.
Vespa (4.5k ⭐) is a comprehensive search engine and vector database. It enables vector search (ANN), lexical search, and structured data search within a single query.
Vald (1.2k ⭐) is a highly scalable distributed dense vector search engine for fast approximate nearest neighbor search.
pgvector (4.1k ⭐) is a PostgreSQL extension that enables storing and querying vector embeddings directly within the database. It is built on top of the Faiss library.
ScaNN (Scalable Nearest Neighbors, Google Research) is a library for efficient vector similarity search. It identifies the k nearest vectors to a query vector based on a similarity metric.
Pinecone is a vector database designed for machine learning applications. It provides speed, scalability, and support for various machine-learning algorithms.
Resources
I write about System Design, UX, and Digital Experiences. If you liked my content, do kindly like and share it with your network. And please don't forget to subscribe for more technical content like this.
Below are some of my popular posts...