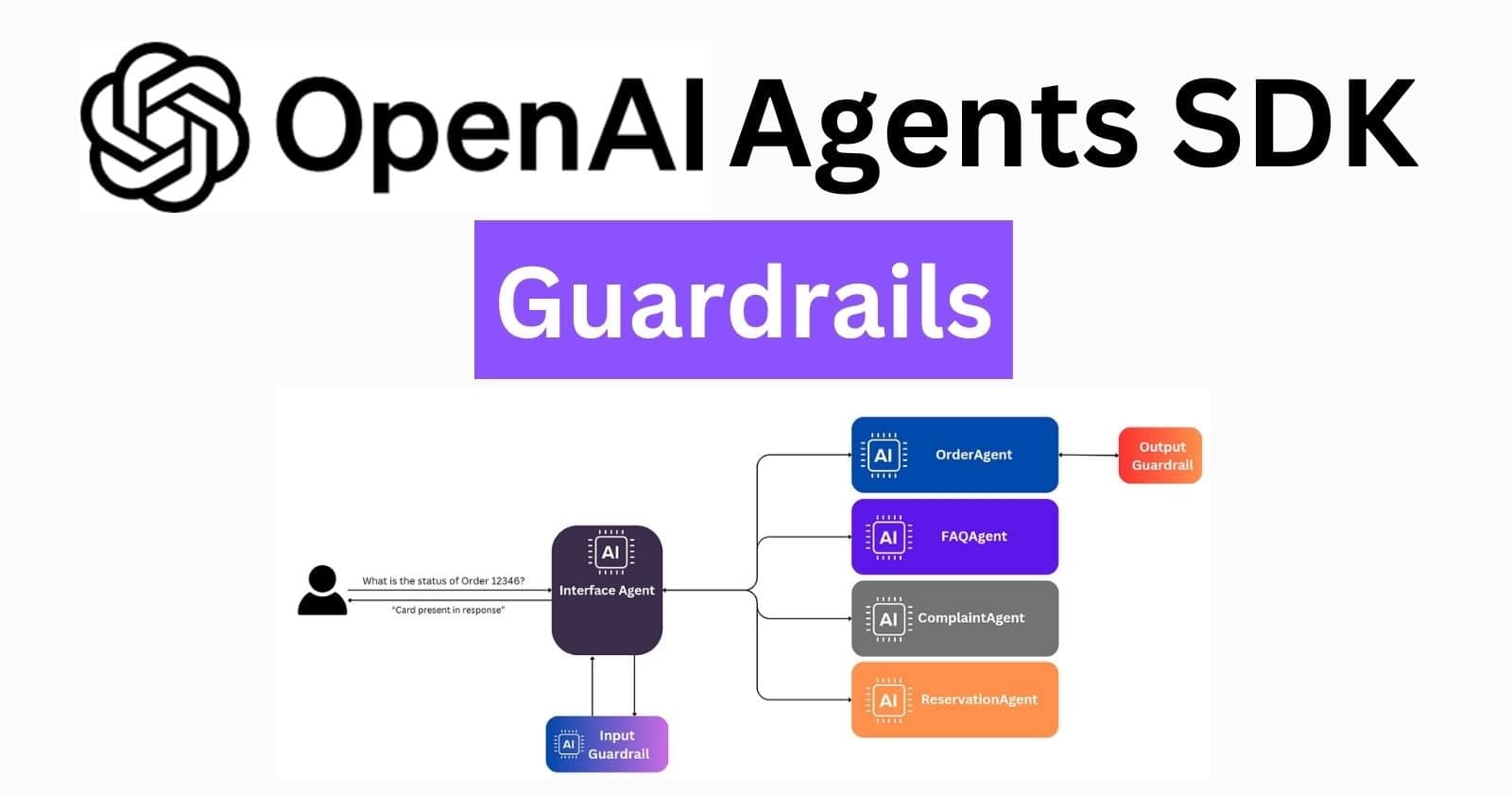
The Context
Ancient civilisations hunted for spice; in the 20th century we fought wars for oil. In 2023, the world’s most precious commodity is an envelope-sized computer chip.
I couldn’t have come up with a better intro than The Telegraph. It perfectly sums up the current scenario.
Despite a price tag of $40000, even superrich countries and companies are struggling to get their hands on it.
Demand for the H100 is so great that some customers are having to wait as long as six months to receive it.
I was of the opinion that AI has evolved at break-neck speed in the last 8 months, apparently, it’s slower - it could have been even faster.

So, what is this H100?
What is the H100?

Named after pioneering computer scientist Grace Hopper, The NVIDIA H100 GPU is a hardware accelerator designed for data centers and AI-focused applications.
A GPU is a type of chip that normally lives in PCs and helps gamers get the most realistic visual experience. The H100 GPU unlike a regular GPU is meant for data processing.
Here are some key details about the H100 GPU:
Tensor Cores: The H100 features fourth-generation Tensor Cores, which are specialized hardware units for accelerating AI computations.
Transformer Engine: The H100 GPU includes a Transformer Engine with FP8 precision, which enables up to 4 times faster training compared to the previous generation.
Architecture: The H100 is based on the NVIDIA Hopper architecture, which is the fourth generation of AI-focused server systems from NVIDIA.
Form Factors: The H100 GPU is available in PCIe and SXM form factors.
Multi-Instance GPU: The H100 GPU supports GPU virtualization and can be divided into up to seven isolated instances, making it the first multi-instance GPU with native support for Confidential Computing.
Performance: According to NVIDIA, the H100 is up to nine times faster for AI training and 30 times faster for inference compared to the previous generation A100 GPU.
What Makes H100 So Special?
The H100 promises significant performance improvements compared to its predecessors. It can deliver up to 9 times faster AI training and up to 30 times faster AI inference in popular machine-learning applications.
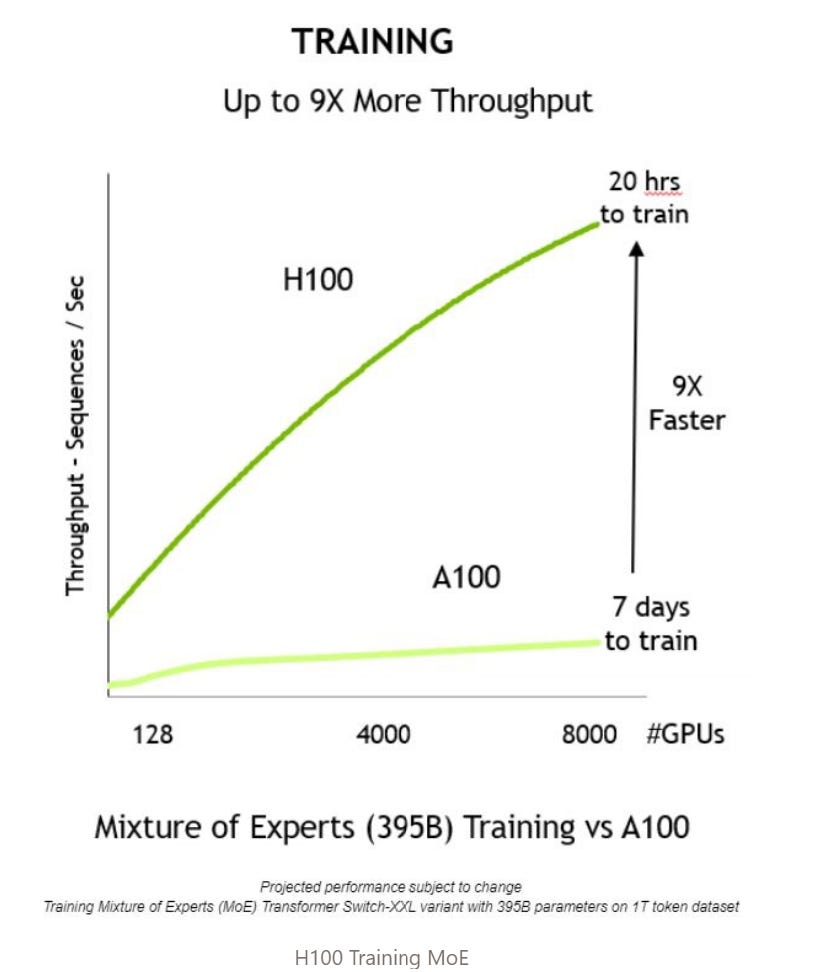
To put things in perspective, GPT-3 was trained with 1024 A100 (H100 predecessor) GPUs in 34 days, while the H100+Codeweaver infrastructure of 3584 GPUs trained GPT-3 in 11 minutes.


Ideal for AI and HPC
The H100 GPU is particularly well-suited for complex AI models and high-performance computing applications. It offers advanced architecture and fourth-generation Tensor Cores, making it one of the most powerful GPUs available.
Best Use Cases (Reference: Lambda Labs)
I write about System Design, UX, and Digital Experiences. If you liked my content, do kindly like and share it with your network. And please don't forget to subscribe for more technical content like this.
My Popular Blog Articles