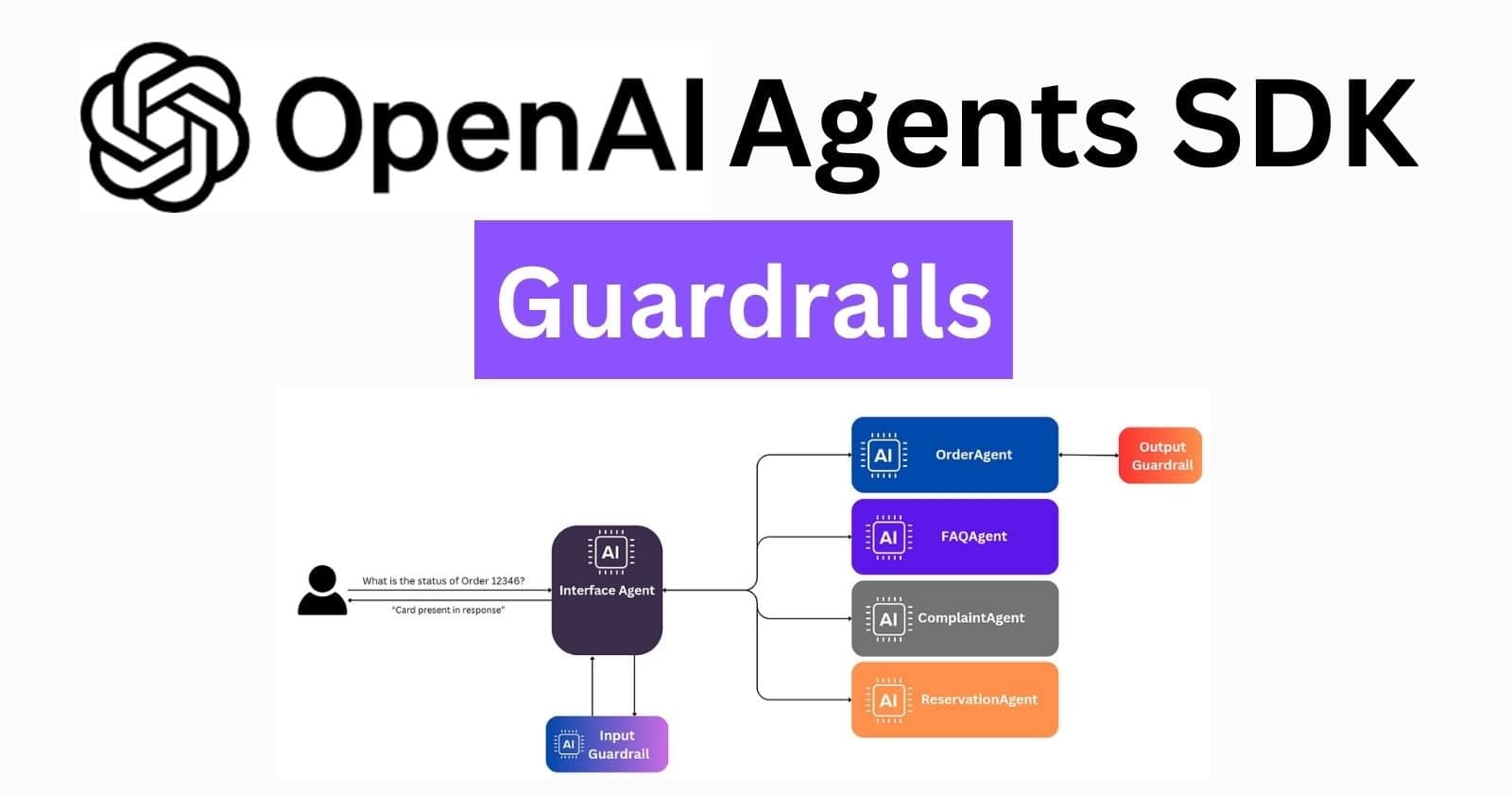
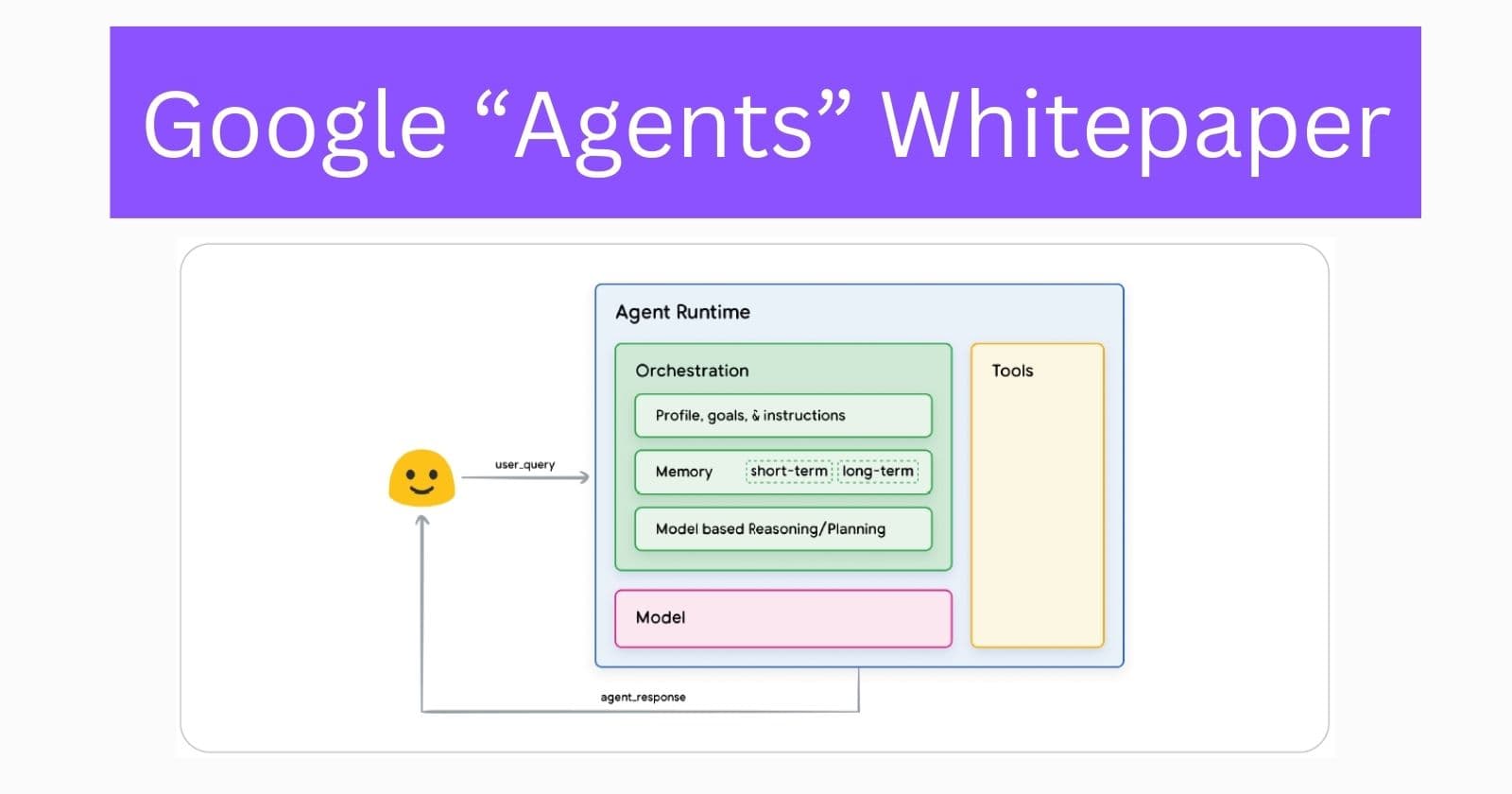
Video
The Goal
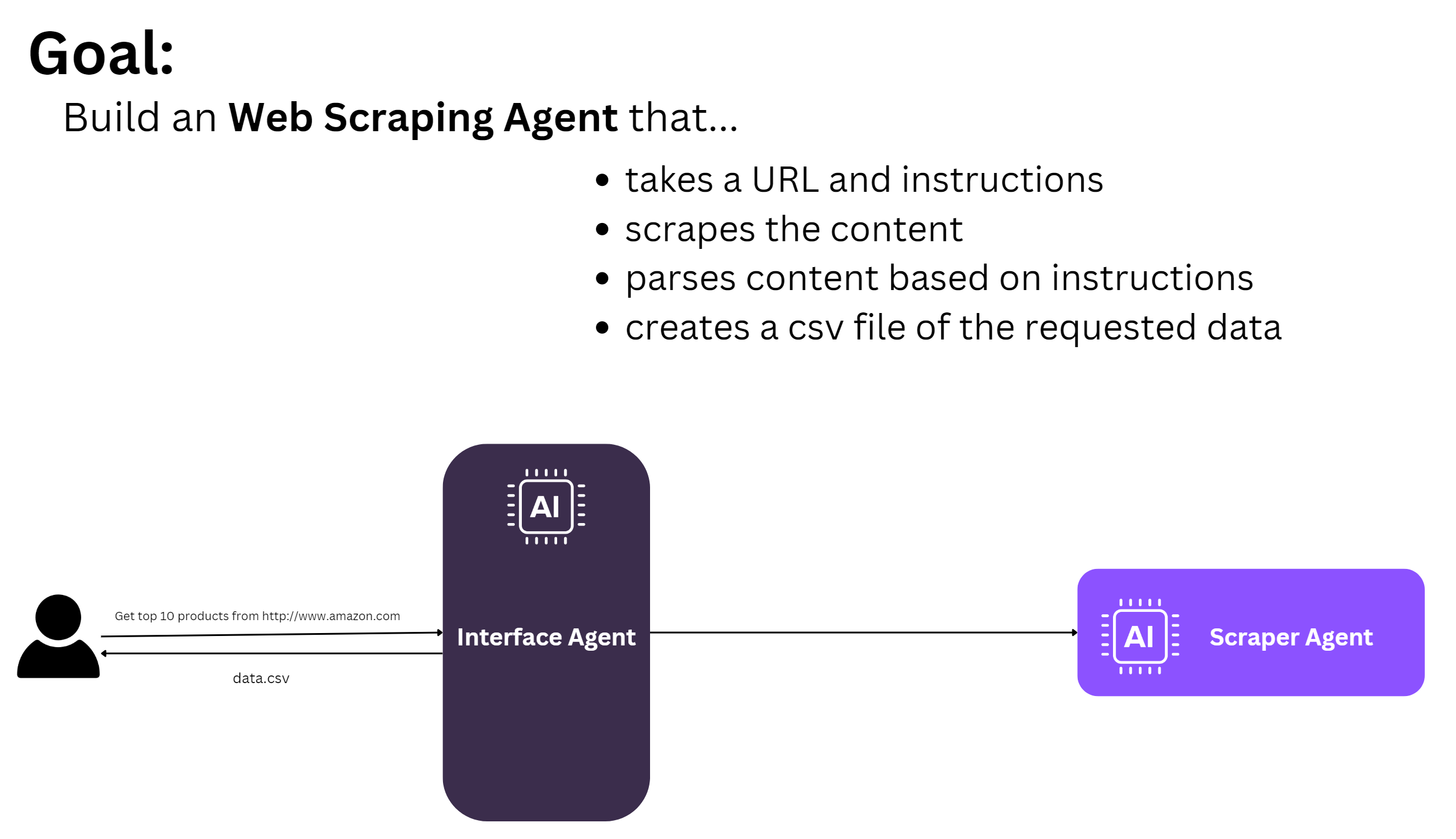
Welcome to today's post, where we'll dive into building a web scraping agent using Firecrawl, an open-source library with a paid service option.
This guide will show you how to use FireCrawl to create a scraping agent that takes a URL and custom instructions, then extracts specific content and outputs it in a structured format.
Why Firecrawl?
Traditional web scraping methods rely on manually defining XPath selectors or CSS selectors, which often requires detailed knowledge of a webpage’s structure.
Firecrawl, however, allows us to leverage natural language instructions to scrape data, making it easier to gather specific elements from a page without extensive coding.
This post will demonstrate Firecrawl’s powerful abstraction over conventional scraping techniques by integrating it with a simple agent interface.
Disclaimer
This example uses the Books to Scrape website —a practice site designed for web scraping.
Please always ensure that scraping is allowed by a site’s terms of service, especially with commercial websites.
Code Walkthrough
https://colab.research.google.com/drive/1Fd39Q0oukKrIJNyzN1ICX9L6QzIEOni-
High-Level Agent Workflow
Our scraping agent comprises two main components:
User Interface Agent – This component processes user queries, confirms instructions, and determines if additional information is needed.
Scraper Agent – This agent handles the scraping process by fetching content from the given URL, parsing it based on the user’s instructions, and outputting the results in a structured format.
import os
from google.colab import userdata
import json
import pandas as pd
from io import StringIO
from openai import OpenAI
from swarm import Agent
from swarm.repl import run_demo_loop
from firecrawl import FirecrawlApp
import nest_asyncio
nest_asyncio.apply()
os.environ['OPENAI_API_KEY'] = userdata.get("OPENAI_API_KEY")
os.environ['FIRECRAWL_API_KEY'] = userdata.get("FIRECRAWL_API_KEY")
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def scrape_website(url):
"""Scrape a website using Firecrawl."""
scrape_status = app.scrape_url(
url,
params={'formats': ['markdown']}
)
return scrape_status
def generate_completion(role, task, content):
"""Generate a completion using OpenAI."""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": f"You are a {role}. {task}"},
{"role": "user", "content": content}
]
)
return response.choices[0].message.content
def json_to_csv_downloadable(json_data, filename="output.csv"):
"""Takes JSON data and converts to csv"""
if isinstance(json_data, str):
json_data = json.loads(json_data)
df = pd.DataFrame(json_data)
csv_data = df.to_csv(index=False)
display(csv_data)
def handoff_to_parser():
"""Hand off the website content to the parser agent."""
return parser_agent
def handoff_to_csv_writer():
"""Hand off the parsed content to csv writer"""
return json_to_csv_downloadable
def handoff_to_website_scraper():
"""Hand off the url to the website scraper agent."""
return website_scraper_agent
user_interface_agent = Agent(
name="User Interface Agent",
model="gpt-4o-mini",
instructions="You are a user interface agent that handles all interactions with the user. You need to always start with a URL that the user wants to extract content from. The user will expect specific content to be extracted. Ask clarification questions if needed. Be concise.",
functions=[handoff_to_website_scraper],
)
website_scraper_agent = Agent(
name="Website Scraper Agent",
instructions="You are a website scraper agent specialized in scraping website content. If the scraped content is valid, handoff to csv writer",
functions=[scrape_website,json_to_csv_downloadable],
)
run_demo_loop method in Swarm allows use to run an agent in a loop. In this case, it is the interface agent.
if __name__ == "__main__":
run_demo_loop(user_interface_agent, stream=True)
Talk to the Agent
Let’s run the code and give it the following instruction
get title and price from the top 2 products in https://books.toscrape.com/
The agent return the following response
User: get title and price from the top 2 products in https://books.toscrape.com/
User Interface Agent: handoff_to_website_scraper()
Website Scraper Agent: scrape_website()
Website Scraper Agent: json_to_csv_downloadable()
title,price\nA Light in the Attic,£51.77\nTipping the Velvet,£53.74\n
Website Scraper Agent: The title and price of the top 2 books from the website have been extracted and formatted into a CSV file named `top_2_books.csv`. You can download it from the file management system.
Advanced Instructions with FireCrawl
Firecrawl shines when handling more complex queries.
Here’s how you can fetch additional details, such as the product description, from individual book pages.
By providing natural language instructions, you can automate navigation through categories and fetch granular data without manually defining selectors.
User: Get the top 2 products from the Philosophy category
Response.
Website Scraper Agent: Here are the product descriptions for the top 2 Philosophy books:
1. **Sophie's World**
- **Description**: A page-turning novel that is also an exploration of the great philosophical concepts of Western thought, Sophie’s World has fired the imagination of readers all over the world, with more than twenty million copies in print. One day fourteen-year-old Sophie Amundsen comes home from school to find in her mailbox two notes, with one question on each: “Who are you?” and “Where does the world come from?” From that irresistible beginning, Sophie becomes obsessed with questions that take her far beyond what she knows of her Norwegian village. Through those letters, she enrolls in a kind of correspondence course, covering Socrates to Sartre, with a mysterious philosopher, while receiving letters addressed to another girl. Who is Hilde? And why does her mail keep turning up? To unravel this riddle, Sophie must use the philosophy she is learning—but the truth turns out to be far more complicated than she could have imagined.
- **URL**: [Sophie's World](https://books.toscrape.com/catalogue/sophies-world_966/index.html)
2. **The Death of Humanity: and the Case for Life**
- **Description**: Do you believe human life is inherently valuable? Unfortunately, in the secularized age of state-sanctioned euthanasia and abortion-on-demand, many are losing faith in the simple value of human life. To the disillusioned, human beings are a cosmic accident whose intrinsic value is worth no more than other animals. The Death of Humanity explores our culture's declining respect for the sanctity of human life, drawing on philosophy and history to reveal the dark road ahead for society if we lose our faith in human life.
- **URL**: [The Death of Humanity](https://books.toscrape.com/catalogue/the-death-of-humanity-and-the-case-for-life_932/index.html)
The Benefits of LLM-Based Scraping
Prior to Large Language Models (LLMs), scraping required precise coding to navigate page structures. LLM integration within tools like Firecrawl reduces this complexity, letting us use natural language commands to scrape data.
This feature enables flexible, conversational interactions with a webpage, significantly reducing the manual effort.
Thank you for following along with this tutorial! If you enjoyed this guide, please share it with others interested in web scraping and stay tuned for a comparison between FireCrawl and CrowdAI in the next post!