Introduction
Before we talk about LLM, it is important to have an understanding of the subsets of Artificial Intelligence.
Natural Langauge Processing

Natural language processing (NLP) is a field of computer science and artificial intelligence that deals with the interaction between computers and human languages. It involves developing algorithms and systems that can understand, generate, and analyze human languages, such as speech and text.
Neural Network

A neural network is a type of computer program that is really good at solving problems and learning new things. It is called a "neural" network because it is inspired by the way that the human brain works.
Just like the brain has lots of tiny cells called neurons that are connected together and work together to help us think, a neural network has lots of tiny computer programs called neurons that are connected together and work together to help it solve problems.
To train a neural network, we give it lots of examples of the problem we want it to solve.
For example, if we want the neural network to recognize different types of animals in pictures, we might show it lots of pictures of animals and tell it what kind of animal is in each picture.
The neural network will try to learn from these examples, and it will become better and better at recognizing different types of animals as it sees more and more examples.
Large Language Model
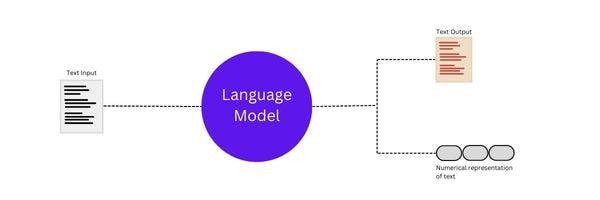
A large language model, or LLM, is a computer program(a deep learning algorithm) that can recognize, summarize, translate, predict, and generate text and other forms of content based on knowledge gained from massive datasets it was 'trained' on.
What is training in the context of the Langauge Model?

Training a model is the process of teaching a computer program to do a specific task.
For example, To teach the model or a computer program to understand and analyze texts, we give the program lots of examples of text to study, such as books, articles, and websites. The program will look at all of these examples and try to figure out the rules of language, such as what words go together and what words mean.
I like this oversimplified explanation from Google.
Imagine training your dog with the commands below. These commands will make your dog a good canine citizen.

However, if you need a special service dog then you add special training.
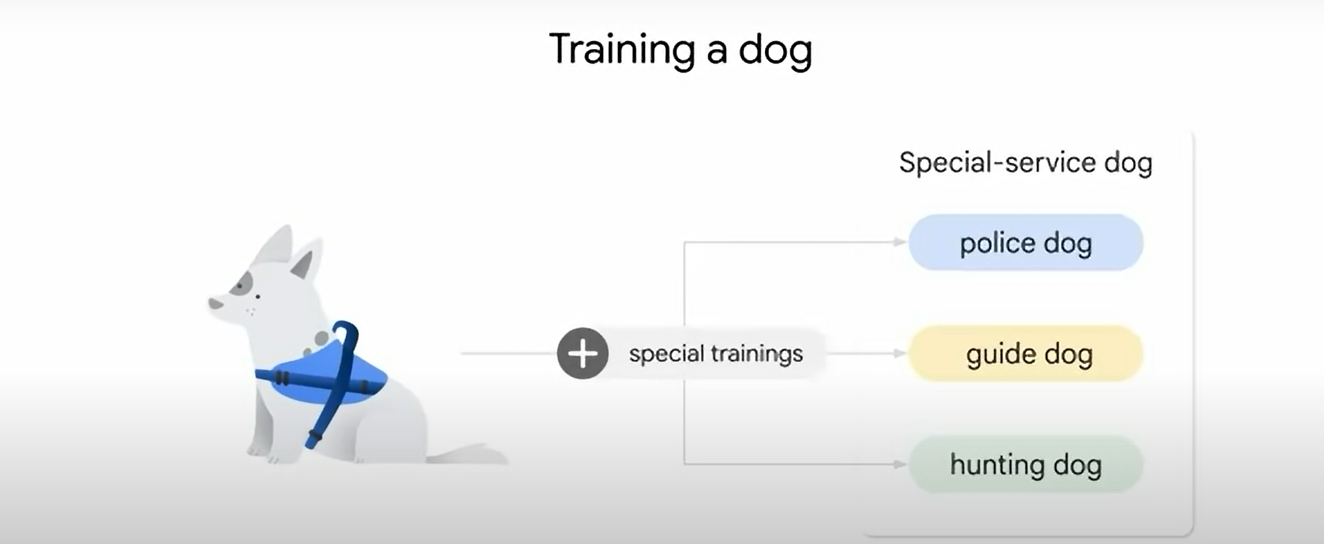
A similar idea applies to large language models.
These models are trained for general purposes to solve common language problems such as Text Classification, QnA, Document Summarization, and Text Generation.
The models can then be tailored (special training) to solve specific problems in different fields like Retail, Finance, Entertainment, etc.
Behind the scene, LLM is a large transformer model that does all the magic.
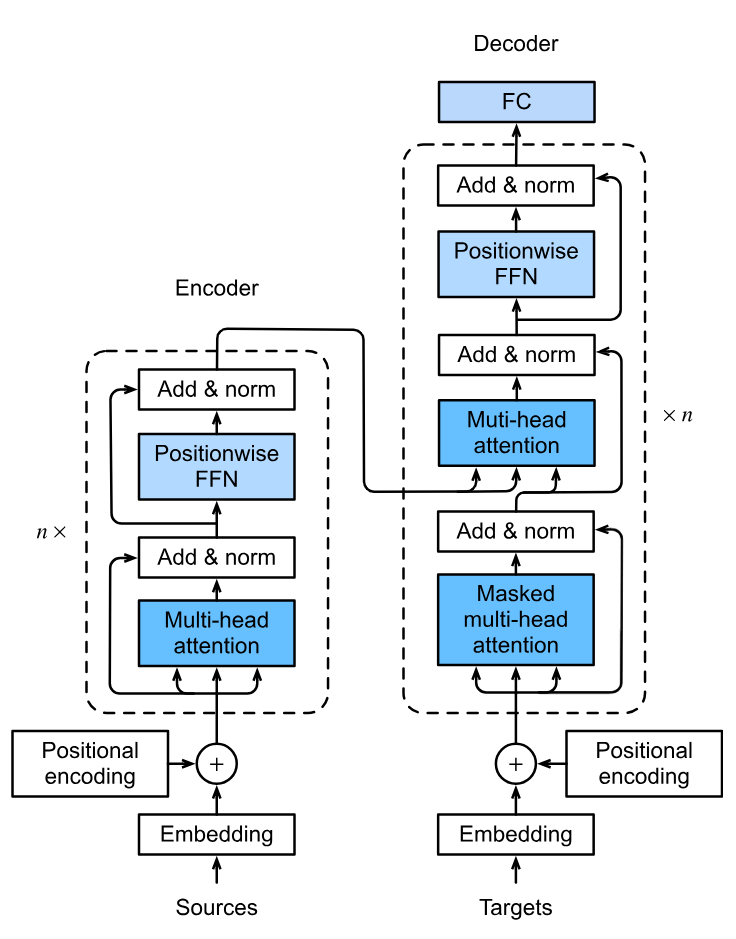
The transformer architecture is a type of neural network that is particularly well suited for natural language processing tasks.

It was introduced in the paper "Attention Is All You Need" by Vaswani et al. (2017) and has since become widely used in a variety of natural language processing and machine translation tasks.
One of its key features is the Self-attention mechanism.
Self-attention mechanisms allow the model to weigh the importance of different input elements such as words or phonemes when generating output.
In a machine translation application, it would take a sentence in one language, and output its translation in another.
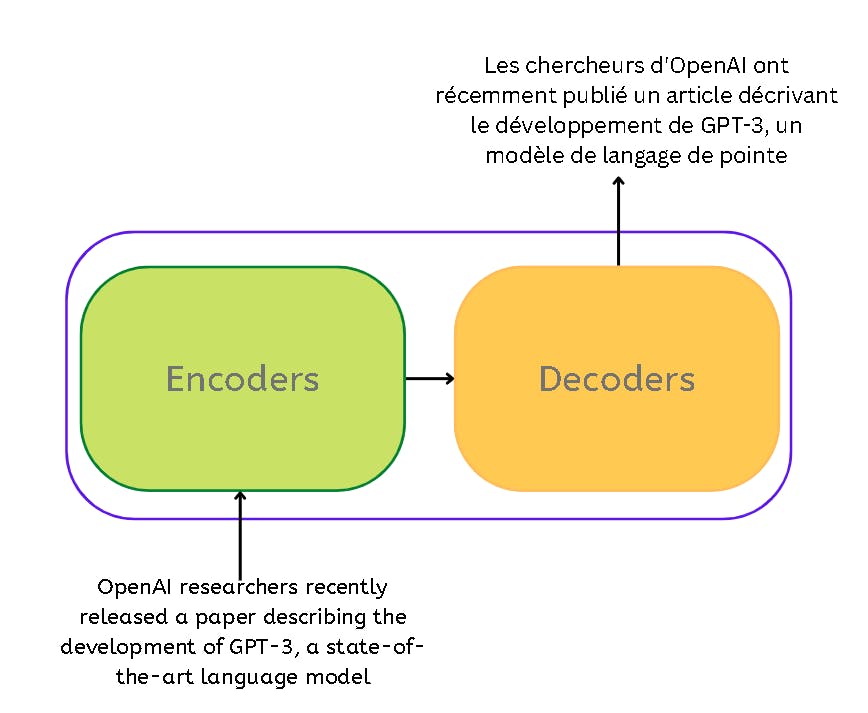
The transformer essentially is the encoder and decoder component with a connection.
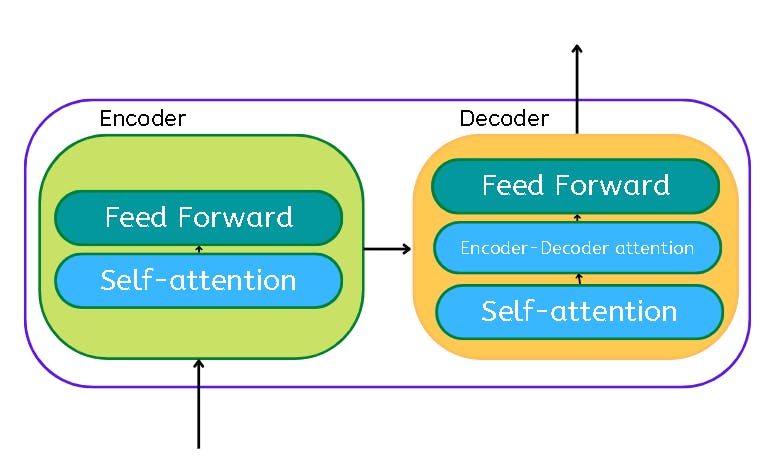
Say the following sentence is an input sentence we want to translate:
”The animal didn't cross the street because it was too tired”
What does “it” in this sentence refer to? Is it referring to the street or to the animal? It’s a simple question to a human, but not as simple to an algorithm.
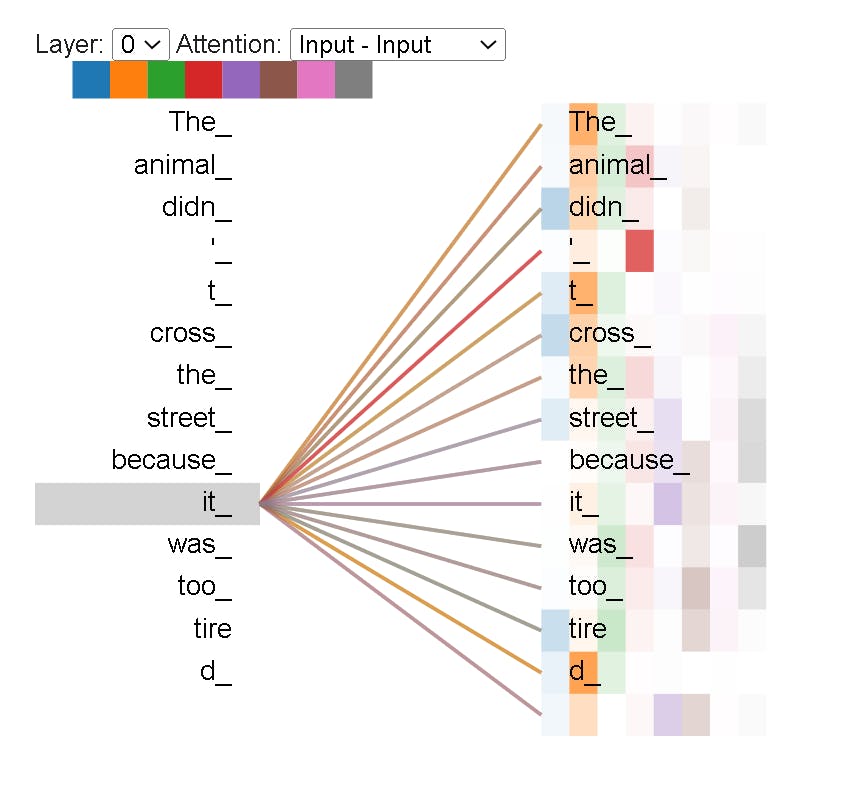
When the model is processing the word “it”, self-attention allows it to associate “it” with “animal”.
As the model processes each word, self-attention allows it to look at other positions in the input sequence for clues that can help lead to a better encoding for this word.
Top Large Language Models
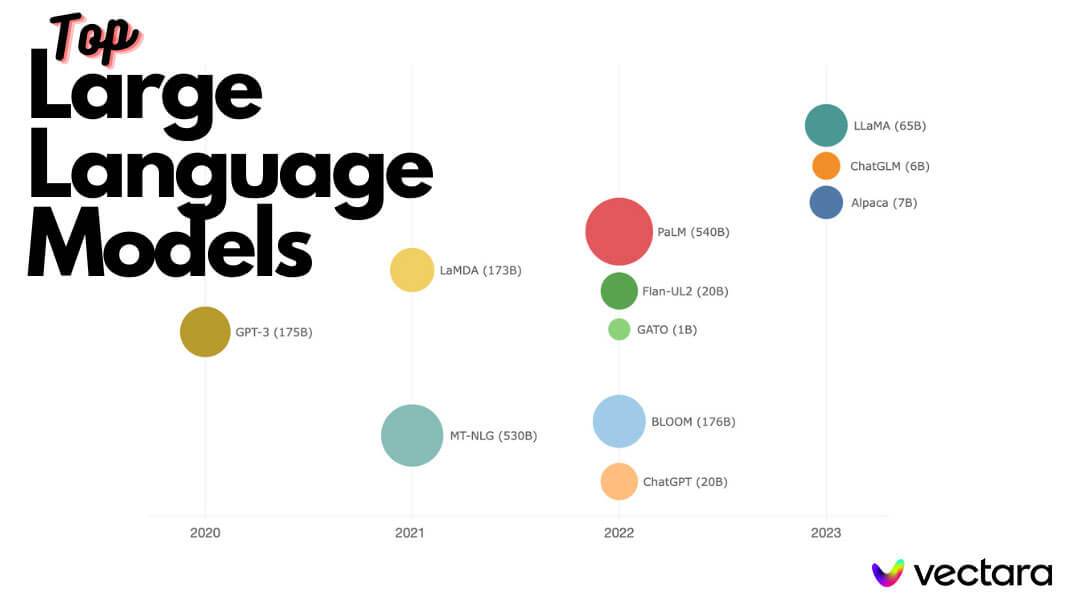
| Name | Created by | Parameters |
| GPT-4 | OpenAI | 1 Trillion (unconfirmed) |
| GPT-3 | OpenAI | 175 Billion |
| Bloom | Collaborative Project | 176 Billion |
| LaMDA | Google | 173 Billion |
| MT-NLG | Nvidia/Microsoft | 530 Billion |
| LLaMA | Meta | 7-65 Billion |
| Stanford Alpaca | Stanford | 7 Billion |
| Flaun UL2 | Google | 20 Billion |
| GATO | DeepMind | 1.2 Billion |
| PaLM | Google | 540 Billion |
| Claude | Anthropic | 52 Billion (unconfirmed) |
| ChatGLM | Tsinghua University | 6 Billion |
LLM AI models are generally compared by the number of parameters — where bigger is usually better.
The number of parameters is a measure of the size and the complexity of the model.
The more parameters a model has, the more data it can process, learn from, and generate.
However, having more parameters also means having more computational and memory resources, and more potential for overfitting or underfitting the data.
Challenges and Limitations of LLM
Development costs: LLMs generally demand expensive graphics processing unit hardware and extensive datasets for efficient operation, resulting in substantial development costs.
Operational costs: Once the training and development phase is complete, the ongoing operational costs of maintaining an LLM can be significantly high for the hosting organization.
Bias: There exists a potential risk of bias in LLMs trained on unlabeled data, as it is not always evident whether known biases have been adequately eliminated.
Explainability: It can be challenging to provide clear explanations regarding how an LLM generated a specific result, posing difficulties for users seeking transparency and interpretability.
Hallucination: In certain instances, LLMs may produce inaccurate responses that are not grounded in the training data, resulting in what is commonly referred to as AI hallucination.
Complexity: Modern LLMs comprise billions of parameters, making them exceptionally intricate technologies that can pose significant challenges in terms of troubleshooting and understanding their inner workings.
Glitch tokens: Since 2022, there has been a rising trend of maliciously designed prompts, known as glitch tokens, which can cause LLMs to malfunction, highlighting a potential security concern.
Conclusion
The world of Large Language Models (LLMs) is rapidly evolving, with new advancements and increasing model parameters emerging at an astonishing pace. It's important to recognize that the true value of an LLM lies in its practical application rather than its mere existence.
While LLMs offer immense potential, their effectiveness depends on how they are harnessed and integrated into real-world scenarios. As the field continues to evolve, it is crucial for software developers to explore and discover the best ways to leverage LLMs in order to unlock their full potential and achieve remarkable outcomes in various domains.
I write about System Design, UX, and Digital Experiences. If you liked my content, do kindly like and share it with your network. And please don't forget to subscribe for more technical content like this.