How ChatGPT Works: The Architectural Details You Need to Know

I am a Journalist-turned-Software Engineer. I love coding and the associated grind of learning every day. A firm believer in social learning, I owe my dev career to all the tech content creators I have learned from. This is my contribution back to the community.
ChatGPT is based on the language model GPT3 or more precisely GPT3.5.
What is GPT?
GPT stands for Generative Pre-trained Transformer. It’s a type of large language model that is trained to generate human-like text.
It is based on the transformer architecture, a type of neural network that is particularly well suited for natural language processing tasks.
In the rest of the article, you are going to see words like model, training, natural language processing, and neural network, a lot.
So it is very important to understand these concepts to comprehend how ChatGPT works.
If you are interested to watch a video version.
Also check out other videos on ChatGPT and Prompt Engineering.
https://www.youtube.com/channel/UCcXAhu4M6Zqc0GU3sVacPhw
What is Natural Langauge Processing?

Natural language processing (NLP) is a field of computer science and artificial intelligence that deals with the interaction between computers and human languages. It involves developing algorithms and systems that can understand, generate, and analyze human languages, such as speech and text.
What is a Language Model?
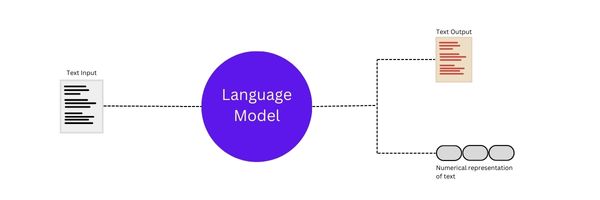
A language model is a type of computer program that helps us understand and analyze language. A well-trained model is good at figuring out the meaning of words and sentences, and it can even translate words from one language to another.
What is training in the context of the Langauge Model?
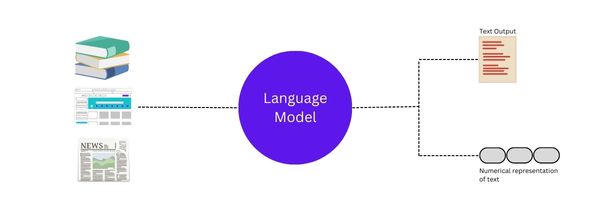
Training a model is the process of teaching a computer program to do a specific task. For example, To teach the model or a computer program to understand and analyze texts, we give the program lots of examples of text to study, such as books, articles, and websites. The program will look at all of these examples and try to figure out the rules of language, such as what words go together and what words mean.
What is a Neural Network?

A neural network is a type of computer program that is really good at solving problems and learning new things. It is called a "neural" network because it is inspired by the way that the human brain works. Just like the brain has lots of tiny cells called neurons that are connected together and work together to help us think, a neural network has lots of tiny computer programs called neurons that are connected together and work together to help it solve problems.
To train a neural network, we give it lots of examples of the problem we want it to solve. For example, if we want the neural network to recognize different types of animals in pictures, we might show it lots of pictures of animals and tell it what kind of animal is in each picture. The neural network will try to learn from these examples, and it will become better and better at recognizing different types of animals as it sees more and more examples.
Now that we have covered some fundamentals - let's get back to ChatGTP.
ChatGPT is based on transformer architecture.

The transformer architecture is a type of neural network that is particularly well suited for natural language processing tasks.

It was introduced in the paper "Attention Is All You Need" by Vaswani et al. (2017) and has since become widely used in a variety of natural language processing and machine translation tasks.
One of its key features is the Self-attention mechanism.
Self-attention mechanisms allow the model to weigh the importance of different input elements such as words or phonemes when generating output.
Let’s begin by looking at the model as a single black box. In a machine translation application, it would take a sentence in one language, and output its translation in another.

The transformer essentially is the encoder and decoder component with a connection.
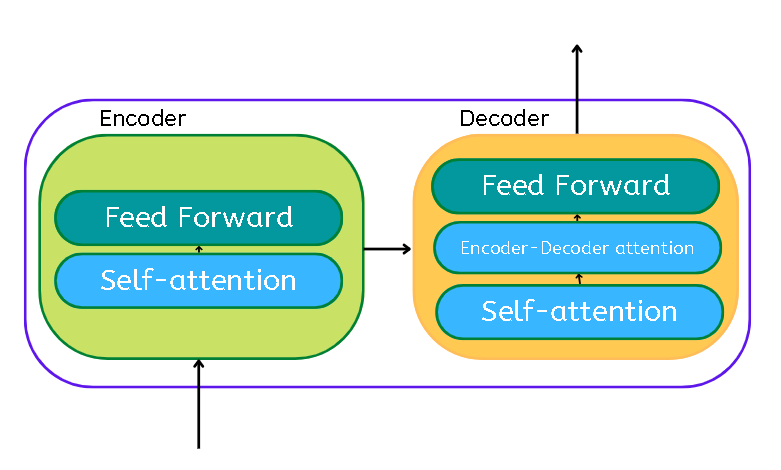
The encoder’s inputs first flow through a self-attention layer – a layer that helps the encoder look at other words in the input sentence as it encodes a specific word.
The outputs of the self-attention layer are fed to a feed-forward neural network.
The decoder has both those layers, but between them is an attention layer that helps the decoder focus on relevant parts of the input sentence
Say the following sentence is an input sentence we want to translate:
”The animal didn't cross the street because it was too tired”
What does “it” in this sentence refer to? Is it referring to the street or to the animal? It’s a simple question to a human, but not as simple to an algorithm.
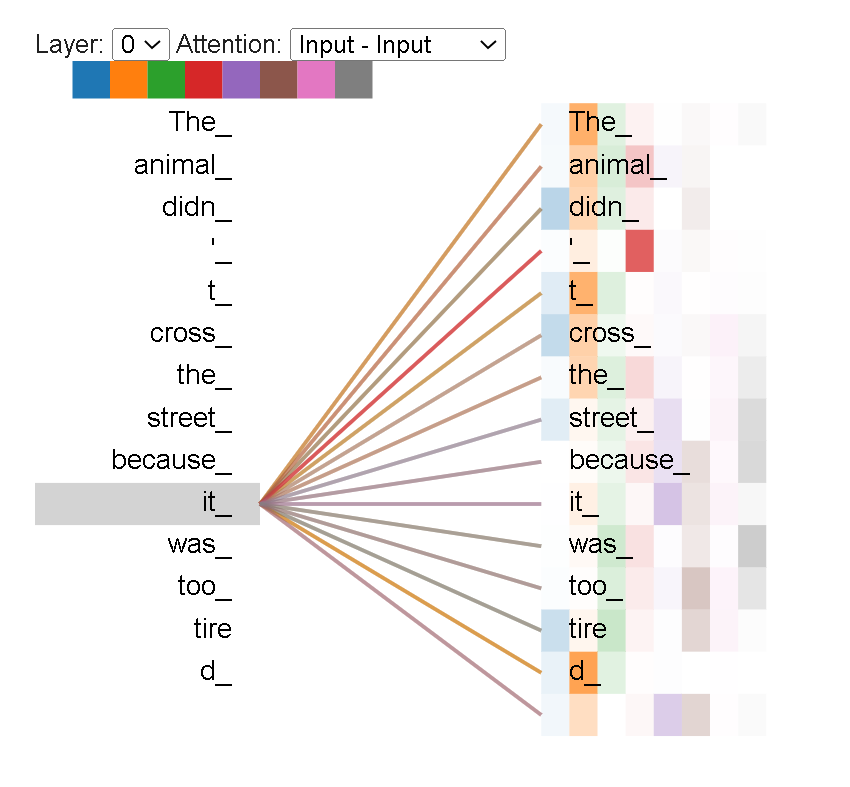
When the model is processing the word “it”, self-attention allows it to associate “it” with “animal”.
As the model processes each word, self-attention allows it to look at other positions in the input sequence for clues that can help lead to a better encoding for this word.
Let’s break it down even further

When translating a sentence from one language to another, self-attention mechanisms might allow the model to pay more attention to certain words or phrases that are more important for understanding the meaning of the sentence.
When generating text that is similar to human-written text, self-attention mechanisms might allow the model to pay more attention to certain words or phrases that are more important for capturing the style or tone of the text.
When analyzing the sentiment (positive or negative) of a piece of text, self-attention mechanisms might allow the model to pay more attention to certain words or phrases that are more indicative of the overall sentiment of the text.
If you liked what you read, please subscribe for interesting articles on System Design, UI/UX, and engineering careers.
Sources:
https://arxiv.org/pdf/1706.03762.pdf
https://pub.towardsai.net/chatgpt-how-does-it-work-internally-e0b3e23601a1
https://towardsdatascience.com/illustrated-self-attention-2d627e33b20a